Since the past one month China is setting high standards in AI field. The same goes for this week also. So without any introduction lets see what happened during this week.
1) HunyuanVideo I2V
Hunyuan released their most awaited Image to Video generator. Parent company of Hunyuan is a Chinese company named Tencent. Yes the same company that develops video games like PUBG.
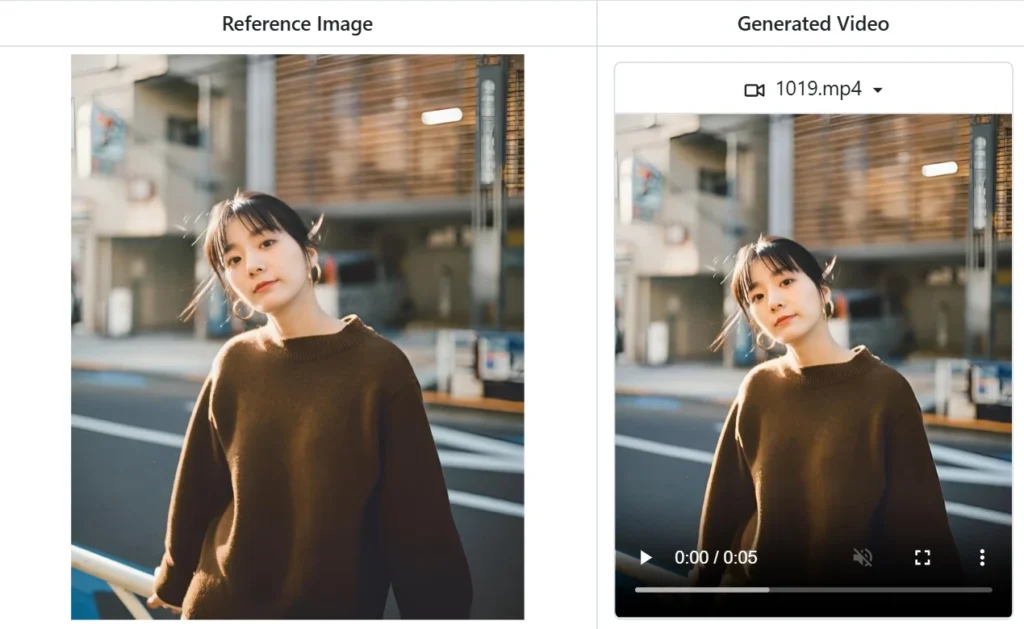
| Type | Opensource |
| Use case | Image to Video Generator |
| Cost | Free |
| Special | Totally Uncensored So You can do anything you want |
| Official GitHub | Click here for official GitHub Page of HunyuanVideo I2V |
| Comfy Ui Setup | Click here for setup Comfy Ui of HunyuanVideo I2V |
2) Spark-TTS
This is new opensource Text to Audio generator. You just need few seconds of source audio (the audio which you want to copy that is it. Once you have it You can use to say anything you want in your source audio.
The cool thing is you can also generate audios in other language also. You can go ahead in official link and hear the samples if you want.
How to use it free? The official GitHub and Hugging face link has all the instruction to use it locally in your computer follow through all instruction and its done.
| Type | Opensource |
| Use case | Text to Audio Generator |
| Cost | Free |
| Official Link (GitHub) | Click here for Official GitHub of Spark-TTS |
| Hugging Face (Use it Locally) | Click here for Official Hugging Face of Spark-TTS |
3) Diffusion Self Distillation (Consistent Image in Different Background)
The name is complex but this model is doing super simplest thing. Now no need to hire any photographer for product photography in different environment. You just need one image of your product and this model can generate the image of the same product in different background.
Just give one sample image and prompt for your background. That is it. You can check out more demos on the official website

| Type | Opensource |
| Use case | Image & Prompt to Same image with Different Background |
| Cost | Free |
| Official Website Link | Click here for Official Website of Diffusion Self Distillation |
| Official GitHub Link | Click here to Visit GitHub of Diffusion Self Distillation |
| Hugging Face | Click here for Official Hugging Face of Diffusion Self Distillation |
4) DiffRythem
It is one of the best AI music Generation model which is completely opensource & free to use. What you will need? A 10 seconds reference song which type of music you want to copy and the lyrics in format like this: [mm:ss.xx]Lyric content. You can generate max of 95 seconds music by this model.
| Type | Opensource |
| Use case | Text to Music Generator |
| Cost | Free |
| Official Website Link | Click here & Visit Official Website of DiffRythem |
| Official GitHub Link | Click to visit Official GitHub of DiffRythem |
| Hugging Face | Click here for Official Hugging Face of DiffRythem |
Conclusion
So, this week many opensource models launched in AI industry. This industry is rapidly changing. We saw Text to Music and Image to Video and product photography models which ultimately is helping other small workers who don’t have enough resources to hire a workers for this kind of things. So this was the latest AI news & models till 10th March 2025.



